Projected Gradient Descent
จากการสร้าง adversarial example ด้วย FGSM สังเกตว่า หากลักษณะความโค้งของ loss function เมื่อเทียบกับ input นั้นไม่เป็น convex จุดที่มีค่า loss สูงสุดในระยะ จาก อาจไม่ใช่จุดมุมที่มีทิศทางตรงกับ gradient ของ loss ที่จุด ก็ได้ เนื่องจากทิศทางของ gradient ก็สามารถเปลี่ยนไปได้เมื่อเราเปลี่ยนตำแหน่งไปจากเดิม แม้ว่าจะห่างจากเดิมน้อยมาก
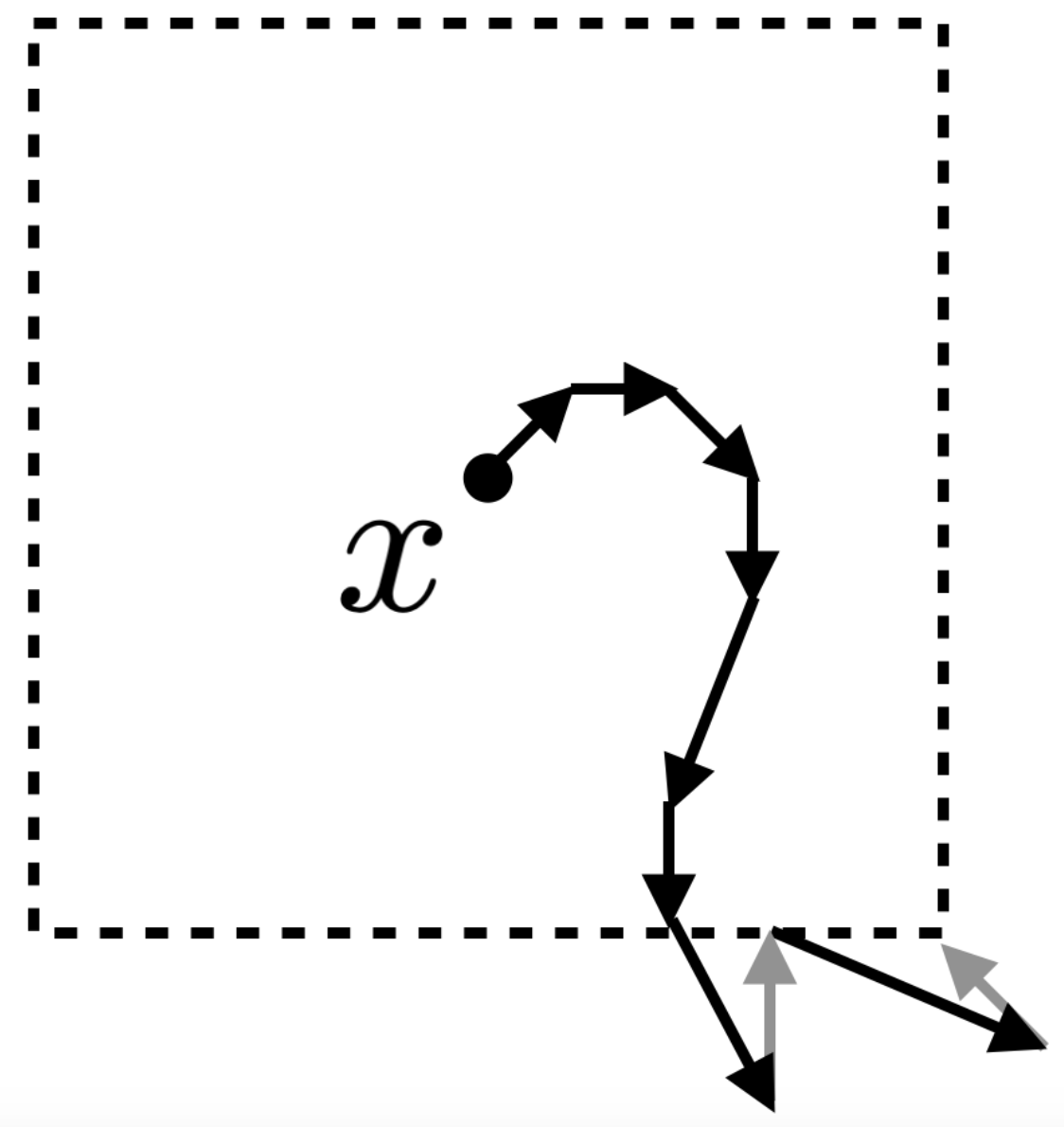
วิธีพื้นฐานในการจัดการปัญหาดังกล่าวก็คือ แทนที่เราจะพิจารณาแค่ gradient ของ loss ที่จุด เพียงจุดเดียว และหาการก่อกวน ตามทิศทางของ gradient ดังกล่าวทันที เราเริ่มจากขยับการก่อกวน ไปเล็กน้อยตามทิศทางของ gradient ที่จุด (หรือจุด เมื่อ ) จากนั้นเราทำการคำนวณ gradient ของ loss ที่จุด ใหม่และขยับ ไปตามทิศทางของ gradient ใหม่นี้ไปเรื่อย ๆ สังเกตว่าวิธีการนี้เหมือนกับการทำ gradient descent ในการปรับค่าของพารามิเตอร์ต่าง ๆ ของแบบจำลองในขั้นตอนการเทรนนั่นเอง โดยเราสามารถกำหนดความไวในการขยับค่า ได้โดยกำหนดค่า learning rate ดังนั้น ถ้าให้ เป็นค่า หลังการขยับในครั้งที่ เราจะสามารถคำนวณ gradient ของ loss เทียบกับ ได้จาก
และการปรับค่า ในรอบที่ ทำได้โดยการคำนวณ จาก ดังนี้
อย่างไรก็ดี เนื่องจากการก่อกวนที่ยอมรับได้นั้นมีขอบเขตจำกัด กล่าวคือ เราจึงต้องคอยระวังไม่ให้การปรับค่า พาเราหลุดออกจากขอบเขตนี้ ซึ่งวิธีหนึ่งที่ทำได้ง่าย ๆ ก็คือ เมื่อใดก็ตามที่ มีค่าในบางมิติมากกว่า เราจะทำการ clip หรือลดค่า ในมิติดังกล่าวลงให้เหลือเท่ากับ เราอาจมองการ clip ค่าของ นี้เป็นการ project ให้กลับเข้ามาอยู่ในขอบเขตที่ต้องการได้ นั่นคือ เราสามารถเขียนกระบวนการวนรอบปรับค่า ได้ดังนี้
เราเรียกวิธีการนี้ว่า projected gradient descent หรือ PGD รูปด้านล่างแสดงตัวอย่างของการทำ PGD
การทดลอง
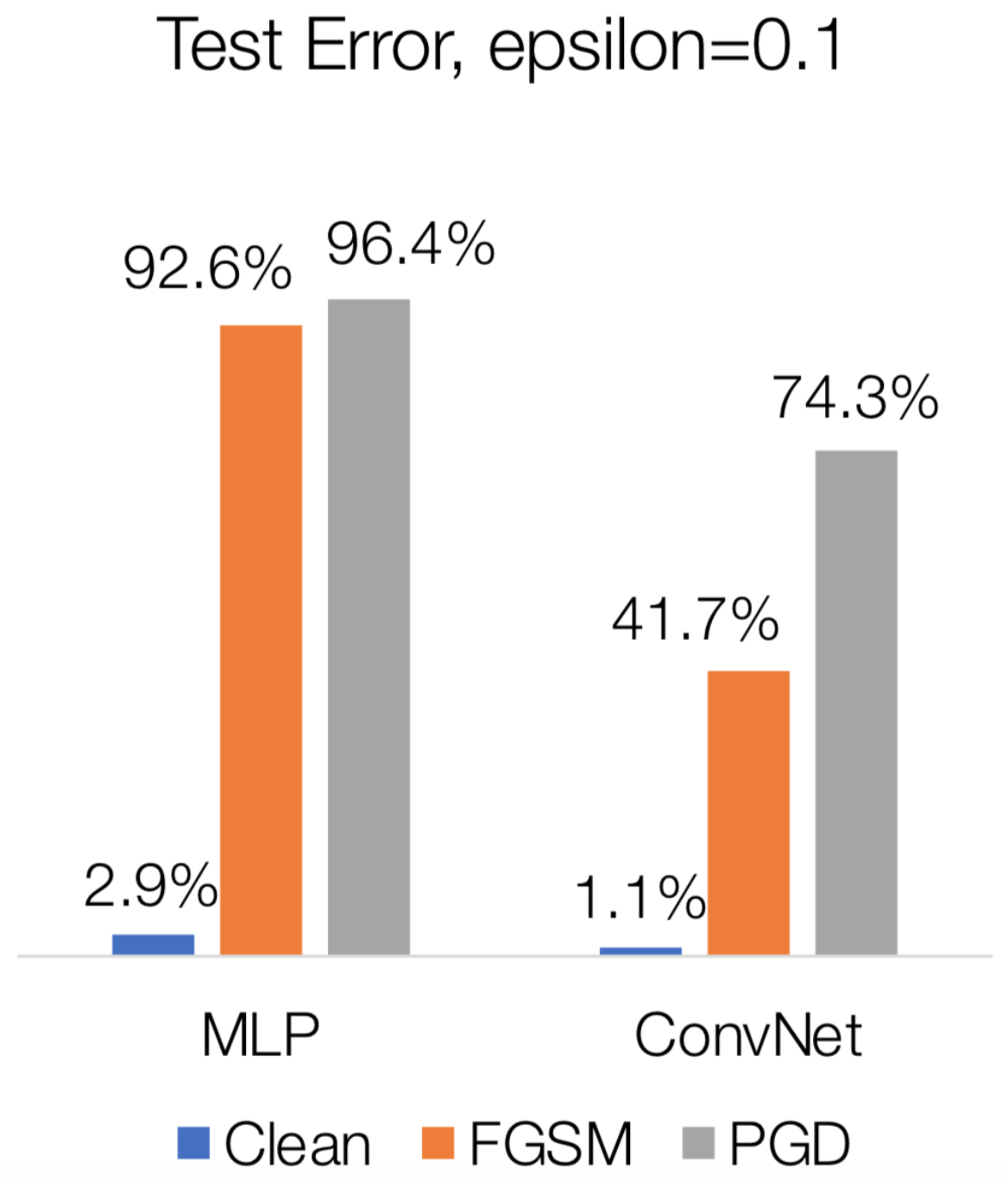
เมื่อเรานำการโจมตีด้วย PGD มาทดสอบกับแบบจำลอง MLP และ CNN ที่ได้ทดสอบด้วย FGSM ไปแล้ว จะเห็นว่า PGD สามารถเพิ่มอัตราความผิดพลาดของแบบจำลองได้ดีกว่า FGSM โดยสามารถเพิ่มอัตราความผิดพลาดให้กับแบบจำลอง MLP เป็น 96.4% และเพิ่มอัตราความผิดพลาดให้กับแบบจำลอง CNN ได้เป็น 74.3% อย่างไรก็ดี เนื่องจากการโจมตีด้วย PGD นั้นเราต้องทำการวนรอบคำนวณการก่อกวน จึงเสียเวลาทำงานตามจำนวนรอบที่ต้องใช้ ในขณะที่ FGSM นั้นสามารถทำการคำนวณผลลัพธ์ได้ทันที FGSM จึงใช้เวลาทำงานเร็วกว่า PGD
References
- Z. Kolter, A. Madry. Adversarial Robustness - Theory and Practice
- A. Madry et al. Towards Deep Learning Models Resistant to Adversarial Attacks. In: International Conference on Learning Representations. 2018
Prev: Fast Gradient Sign Method
Next: Adversarial training