Fast Gradient Sign Method
จากแบบจำลองเชิงเส้นสู่ deep learning
หลังจากที่เราได้รู้จักการสร้าง adversarial example และการทำ robust optimization ในแบบจำลองที่เป็นเชิงเส้นกันมาแล้ว เรามาลองพิจารณาบนแบบจำลอง deep neural network กันดูบ้าง ปัญหาแรกที่เราสนใจคือปัญหาการสร้าง adversarial example สำหรับตัวอย่างข้อมูล ใด ๆ ซึ่งมองเป็นปัญหา optimization ได้ดังนี้
โดยในคราวนี้เราจะให้ แทนแบบจำลอง deep neural network ที่มี layer ซึ่งสามารถอธิบายได้ด้วยสมการต่อไปนี้
เมื่อ แทนค่าที่จะถูกส่งเข้าไปคำนวณใน layer ที่ ซึ่งมี activation function เป็น โดย activation function ที่นิยมในปัจจุบันคือ ReLU สำหรับ layer และ สำหรับ parameter ที่ถูกปรับค่าระหว่างการเทรนนั้นคือ และ loss function ที่เราใช้ในการเทรนก็คือ softmax cross entropy
ในกรณีของ deep neural network นั้นการแก้ปัญหา maximization สำหรับสร้าง adversarial example ไม่สามารถทำได้ง่ายเหมือนแบบจำลองเชิงเส้น เนื่องจากลักษณะของ loss function เป็น non-convex เราจึงสนใจการประมาณค่าให้ได้ใกล้เคียงที่สุด
Fast Gradient Sign Method
หนึ่งในอัลกอริทึมกลุ่มแรกที่ถูกเสนอสำหรับสร้าง adversarial example บนแบบจำลอง deep learning นี้เรียกว่า Fast Gradient Sign Method หรือ FGSM
พิจารณาปัญหา maximization เมื่อขอบเขตการก่อกวนอยู่ในรูปของ -norm ลักษณะขอบเขตของการก่อกวนสำหรับตัวอย่างข้อมูล แสดงได้ดังรูปด้านล่าง
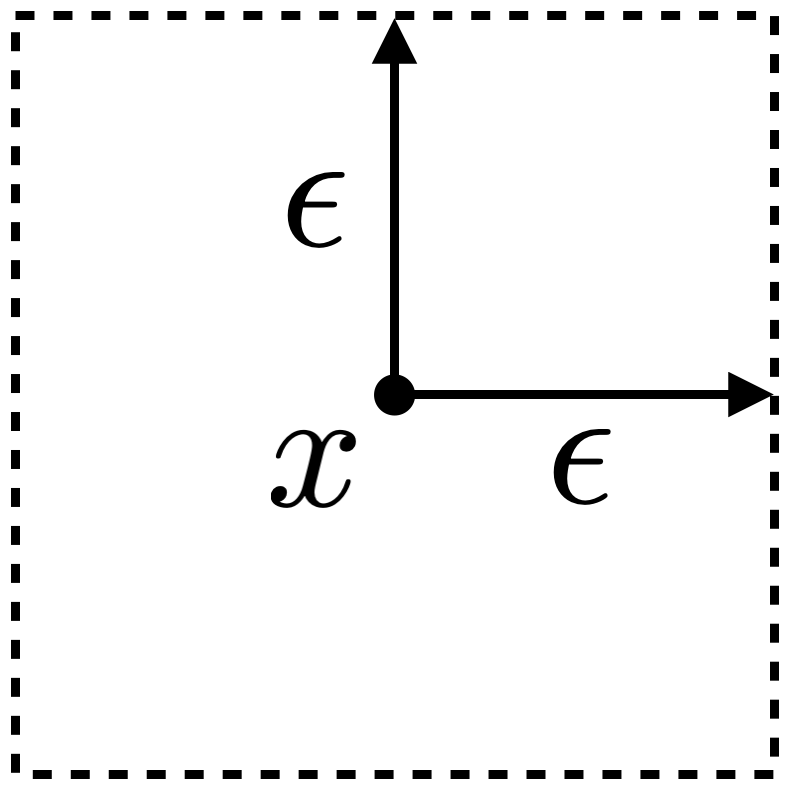
แนวทางพื้นฐานในการแก้ปัญหา optimization ก็คือการทำ gradient descent ซึ่งในกรณีนี้เราต้องการปรับค่า ให้ loss มีค่าสูงที่สุด เราต้องเริ่มจากการคำนวณ gradient ของ loss เมื่อเทียบกับ ก่อน กล่าวคือเราคำการหา
โดยใช้ backpropagation และทำการปรับ ไปตามทิศทางของ
เมื่อ เป็น learning rate อย่างไรก็ดี การปรับ เช่นนี้อาจพาเราออกไปนอกขอบเขตของ ที่เป็นไปได้หาก มีขนาดใหญ่เกินไป เมื่อเกิดเหตุการณ์ดังกล่าวเราสามารถแก้ปัญหาได้โดยการ project กลับมาให้อยู่ภายในบริเวณที่ต้องการ รูปด้านล่างแสดงตัวอย่างเมื่อ พาเราออกไปนอกขอบเขต เมื่อเรา project ให้กลับมาอยู่ในขอบเขตของ -norm จะทำให้ได้ adversarial example เป็นข้อมูลที่อยู่ที่จุดมุมขวาบนของกรอบสี่เหลี่ยม
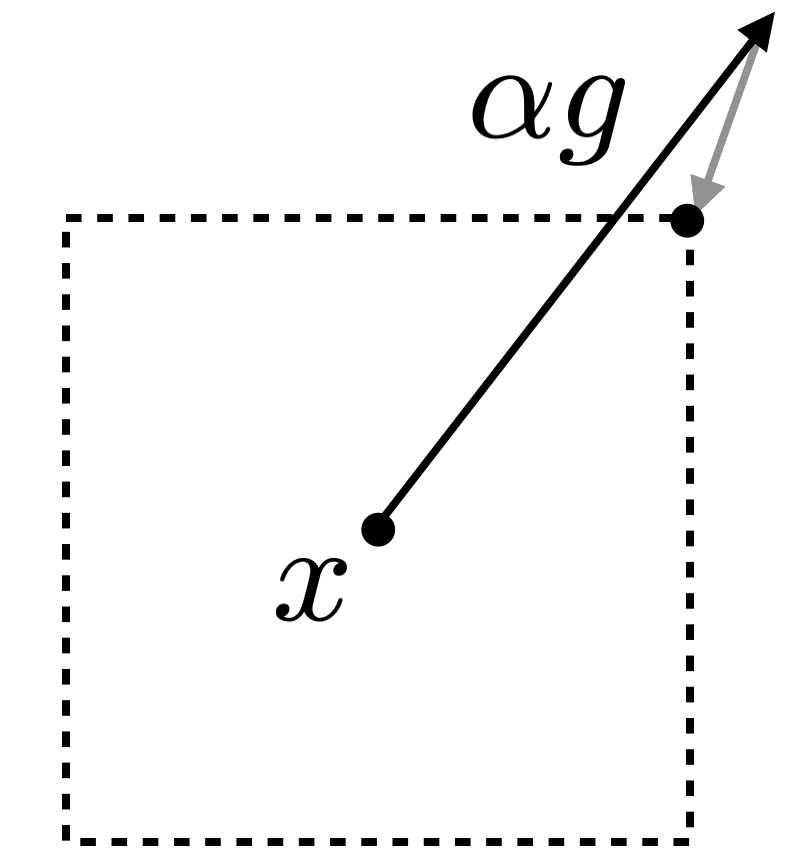
จากตัวอย่างจะเห็นว่า ในกรณีของ -norm นี้การ project กลับมาทำได้ง่ายโดยการ clip ค่าของ ในแต่ละมิติให้อยู่ในช่วง และเมื่อ มีขนาดใหญ่พอ เราจะได้ผลอยู่ที่จุดมุมของขอบเขตเสมอ ซึ่งจุดมุมดังกล่าวสามารถหาได้โดยการกำหนดให้ เป็น หรือ ตามทิศทางของ นั่นคือ
เราเรียกกระบวนการสร้าง adversarial example ด้วยวิธีนี้ว่า Fast Gradient Sign Method ซึ่งสามาถคำนวณได้รวดเร็ว เนื่องจากใช้การคำนวณ gradient เพียงครั้งเดียวเท่านั้น
การทดลอง
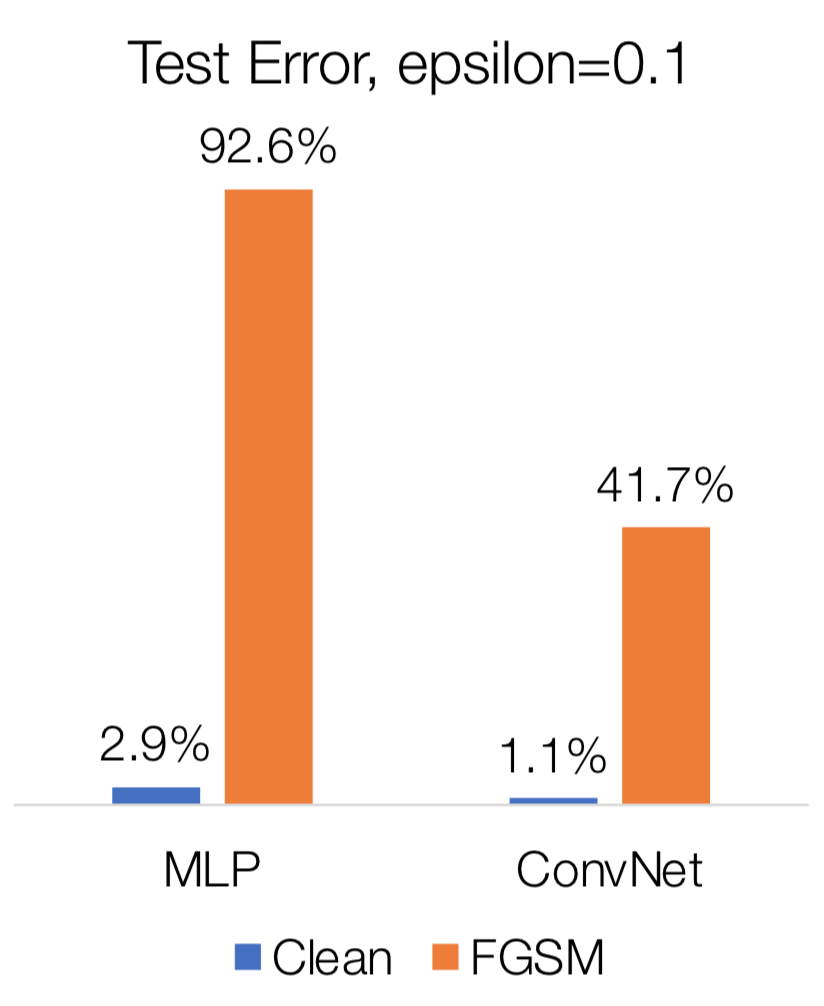
ใน Adversarial Robustness - Theory and Practice ได้ทำการทดลองกับแบบจำลองสองตัว ได้แก่ fully connected multi-layer perceptron (MLP) จำนวน 2 layer และ convolutional neural network (CNN) จำนวน 6 layer กับชุดข้อมูล MNIST
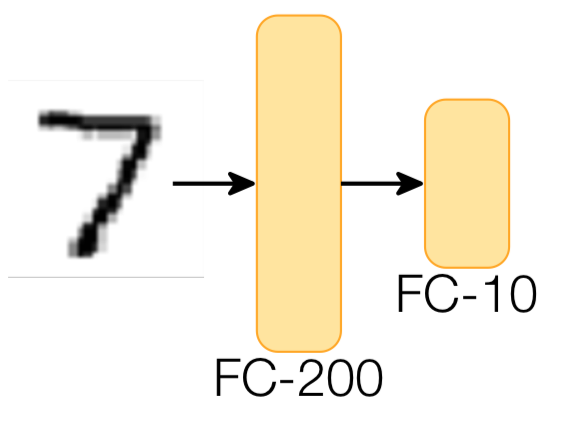
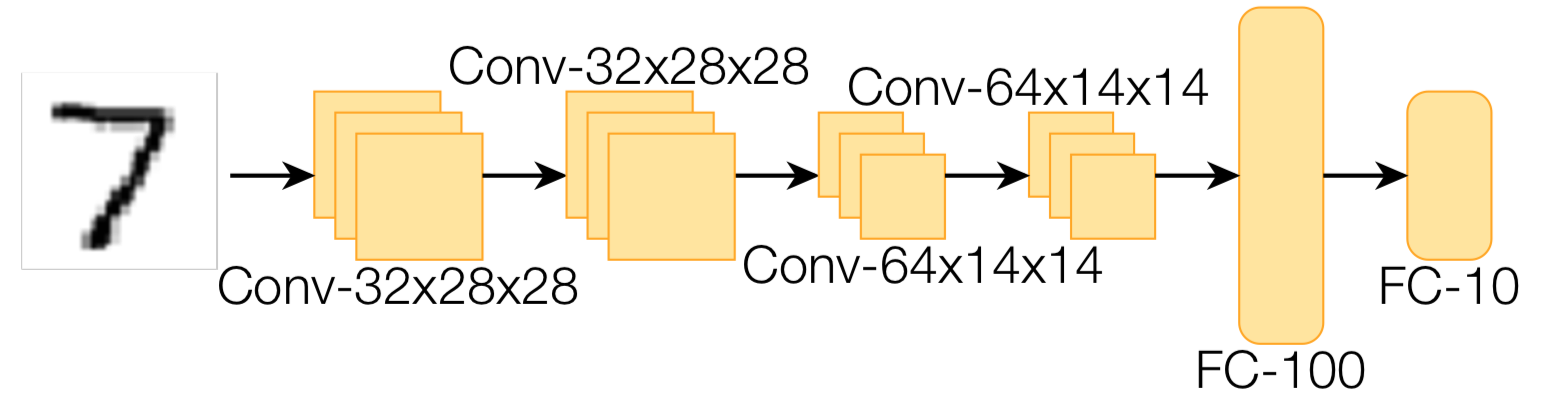
รูปด้านล่างแสดงความผิดพลาดของแบบจำลองทั้งคู่ เมื่อทดสอบด้วยชุดข้อมูลทดสอบธรรมดา (clean) และชุดข้อมูลทดสอบที่ถูกก่อกวนด้วย FGSM โดยใช้ จะเห็นว่า FGSM สามารถทำให้อัตราผิดพลาดของแบบจำลอง fully connected MLP เพิ่มจาก 2.9% เป็น 92.6% ในขณะที่อัตราผิดพลาดของแบบจำลอง CNN เพิ่มจาก 1.1% เป็น 41.7%
สังเกตว่าหากแบบจำลองของเราเป็น linear binary classification โดยมีขอบเขตการก่อกวนเป็น -norm FGSM จะให้ผลลัพธ์เป็นคำตอบที่ดีที่สุด อย่างไรก็ดี เรารู้ว่าสำหรับ deep neural network นั้นลักษณะของ loss function ไม่ได้มีทิศทางเป็น linear แม้ในบริเวณเล็ก ๆ ดังนั้นการพุ่งไปยังทิศทางของ gradient โดยตรงในครั้งเดียวนี้อาจไม่ได้พาเรามุ่งหน้าไปหาจุดที่ loss สูงสุดตามต้องการจริง ๆ หากเราต้องการการโจมตีที่ได้ผลดีกว่านี้ เราก็ต้องมีวิธีค้นหาจุดที่ค่า loss สูงที่ดีกว่านี้
References
- Z. Kolter, A. Madry. Adversarial Robustness - Theory and Practice
- I. Goodfellow, J. Shlens, C. Szegedy. Explaining and Harnessing Adversarial Examples, In: 3rd International Conference on Learning Representations, 2015