ความสามารถของ weak feature
หลังจากที่เราได้เห็นความสามารถในการตัดสินใจของ robust feature กันมาแล้ว คราวนี้เราจะมาลองดูความสามารถของ weak feature กันดูบ้าง โดยเราจะสร้างชุดข้อมูลใหม่ที่ทำให้ robust feature ทั้งหมดไม่สามารถใช้ช่วยในการตัดสินใจได้ นั่นคือเราจะทำให้ในชุดข้อมูลใหม่นั้นมีเพียง weak feature ที่ยังคงเป็น useful feature อยู่ จากนั้นเราจะนำชุดข้อมูลที่ได้ไปเทรนแบบจำลองและนำมาทดสอบกับ test data เดิมของเราดูเช่นเดียวกับการทดสอบความสามารถของ robust feature ก่อนหน้านี้
การสร้าง weak-feature training set
ในการสร้างชุดข้อมูลให้มีเฉพาะ weak feature เท่านั้นที่เป็น useful feature เราเริ่มจากการสร้าง standard classifier $C$ ซึ่งไม่มีความทนทานต่อการโจมตี จากนั้น สำหรับตัวอย่างข้อมูล $(x,y)$ แต่ละตัวใน training set เราจะสร้างตัวอย่างข้อมูลใหม่ $(x’,y’)$ ด้วยวิธีการดังนี้
เราจะสุ่มคลาสเป้าหมาย $y’$ จากคลาสทั้งหมดให้มีความน่าจะเป็นที่จะได้แต่ละคลาสเท่ากัน จากนั้นเราจะทำการโจมตีแบบกำหนดเป้าหมายเพื่อหา adversarial example $x’$ ที่ $C$ ทำนายว่าเป็นคลาส $y’$ โดยให้การก่อกวนมีขนาดเล็ก ๆ (ไม่เกิน $\epsilon$) การหา adversarial example $x’$ ดังกล่าวทำได้โดยการทำ gradient descent เพื่อหา
โดย $\mathcal{L}_C$ แทนฟังก์ชัน loss จาก classifier $C$ เมื่อเราหา $x’$ ดังกล่าวได้แล้ว ก็จะได้ตัวอย่างข้อมูลใหม่เป็น $(x’, y’)$ ตามต้องการ
เราจะมาทำความเข้าใจกันก่อนว่าชุดของตัวอย่างข้อมูลที่สร้างขึ้นด้วยกระบวนการนี้จะทำให้มีเฉพาะ weak feature ที่แบบจำลองสามารถนำไปใช้งานได้อย่างไร ก่อนอื่นสังเกตว่าเนื่องจาก adversarial example $x’$ นั้นมีความใกล้เคียงกับ $x$ อย่างมาก นั่นแสดงว่า robust feature ต่าง ๆ ของ $x’$ จะยังคง ชี้ ไปยังคลาส $y$ เช่นเดิม ดังนั้นการที่ $C$ ทำนายคลาสของ $x’$ ไปเป็น $y’$ ได้นั้น แสดงว่าจะต้องมี weak feature ที่ชี้ไปหาคลาส $y’$ นั่นเอง
เนื่องจากสำหรับตัวอย่างข้อมูล $(x,y)$ แต่ละตัว เราเลือกคลาส $y’$ ใหม่โดยการสุ่ม ดังนั้นจะเห็นว่าในบรรดาตัวอย่างข้อมูลเดิมที่เป็นคลาส $y$ เหมือนกัน อาจจะถูกโจมตีให้กลายเป็นคลาสเป็นคลาสที่แตกต่างกันอย่างไรก็ได้ ทั้ง ๆ ที่ตัวอย่างข้อมูลทั้งหมดนี้จะยังคงมี robust feature ที่ชี้ไปทิศทางเดียวกัน ตรงนี้ทำให้เห็นว่าในชุดข้อมูลใหม่ที่สร้างขึ้นมานั้น โดยเฉลี่ยแล้ว robust feature จะไม่มีทางเป็น useful feature ได้
ในทางกลับกัน ในชุดข้อมูลใหม่ เรากำหนด label $y’$ ให้ตรงกับที่ $C$ ทำนายจาก $x’$ เสมอ แต่เนื่องจาก $x’$ แต่ละตัวนั้นไม่สอดคล้องกับ label $y’$ เลยในสายตามนุษย์ แสดงว่า feature ที่ทำให้ $C$ ตัดสินใจทำนายคลาสของ $x’$ เป็น $y’$ นั้นจะต้องเป็น weak feature นั่นคือ ใน adversarial example $x’$ จะมี weak feature ของคลาส $y’$ อยู่ ดังนั้นเมื่อเรากำหนดให้ชุดข้อมูลใหม่ของเราประกอบด้วยตัวอย่างข้อมูล $(x’, y’)$ ทั้งหมด ก็จะทำให้ weak feature เหล่านี้ยังคงใช้งานได้เช่นเดิม โดยสรุป หากเราเรียกชุดข้อมูลใหม่นี้ว่า $\widehat{D}_{rand}$ เราจะได้ว่า
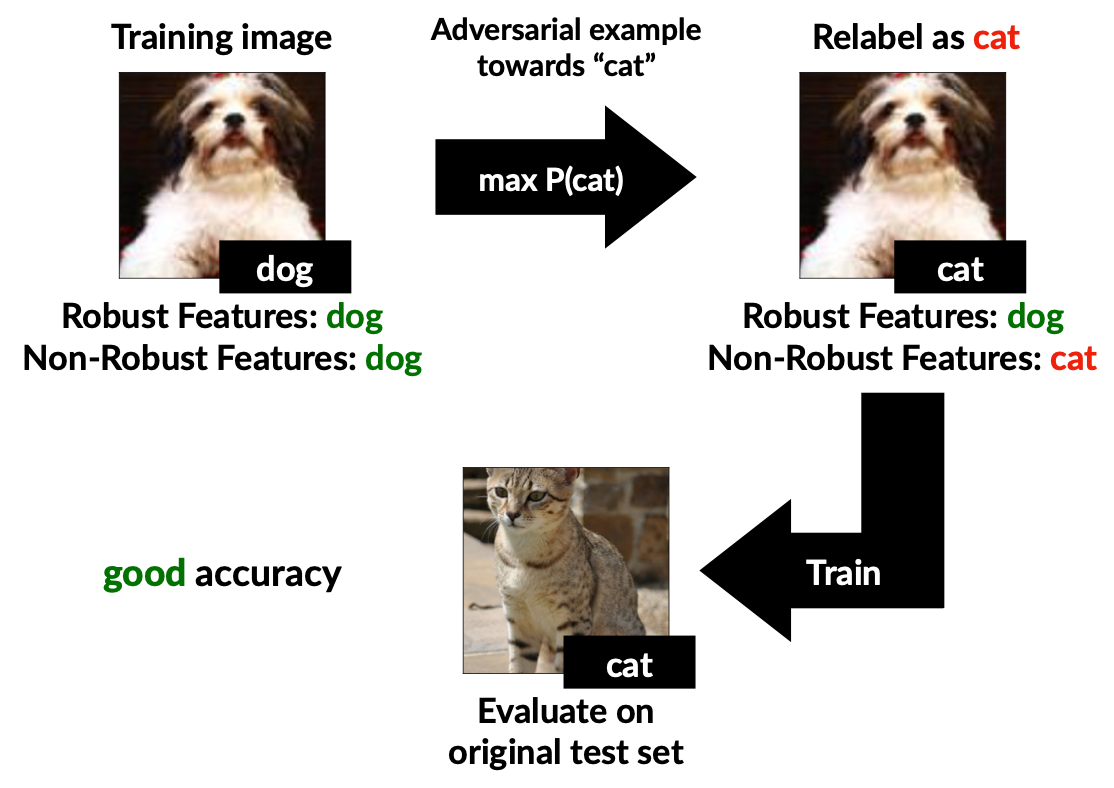
เมื่อเราได้ชุดข้อมูล $\widehat{D}_{rand}$ มาแล้ว เรานำชุดข้อมูลนี้มาเทรนแบบจำลองขึ้นใหม่โดยใช้ standard training จากนั้นนำไปทดสอบกับ test set ดั้งเดิม เราพบว่าแบบจำลองใหม่มีความแม่นยำในการทำนายที่สูง ทั้ง ๆ ที่ข้อมูลที่ใช้ในการเทรนนั้นมี label แทบจะไม่ถูกเลยในสายตามนุษย์ โดยเมื่อทดสอบโดยใช้ชุดข้อมูล CIFAR-10 จะได้ความแม่นยำที่ 63.3% และเมื่อทดสอบกับชุดข้อมูล $\text{ImageNet}_R$ ซึ่งเป็นชุดข้อมูล $\text{ImageNet}$ ขนาดย่อม สามารถได้ความแม่นยำถึง 87.9 % เนื่องจากความแม่นยำนี้เกิดจากการตัดสินใจบน weak feature เท่านั้น เราจะเห็นได้ชัดเจนว่า weak feature มีบทบาทในการทำนายของแบบจำลองเป็นอย่างมาก
ภาพด้านล่างแสดงผลการทดลองนี้โดยรวม
การทดสอบแบบประชัน
ถึงตรงนี้เราจะทำการดัดแปลงการทดลองด้านบนเล็กน้อย โดยในขั้นตอนการสร้างชุดข้อมูลใหม่ สำหรับตัวอย่างข้อมูล $(x, y)$ แต่ละตัว แทนที่เราจะสุ่มคลาสปลายทาง $y’$ เราจะทำการเลือก $y’$ โดยอิงจาก $y$ โดยมีเป้าหมายให้ข้อมูลจากคลาสเดิมคลาสเดียวกันมีคลาสเป้าหมายเป็นคลาสเดียวกัน วิธีหนึ่งที่ทำได้คือ เรากำหนดคลาสเป้าหมายเป็น
เมื่อ $c$ เป็นจำนวนคลาสทั้งหมด เราเรียกชุดข้อมูลใหม่ที่สร้างด้วยวิธีนี้ว่า เนื่องจากตัวอย่างข้อมูลในคลาส $y$ ทั้งหมดต่อให้ถูกโจมตีเป็น $x’$ แล้วก็จะยังคงมี robust feature ชี้ไปยังคลาส $y$ เหมือนกัน ในขณะที่ weak feature ใน $x’$ จะชี้ไปยังคลาส $y’$ ทั้งสิ้น นั่นคือ
ดังนั้นหากเรานำชุดข้อมูลใหม่นี้ ไปเทรนแบบจำลองขึ้นใหม่ เราจะได้ว่า robust feature จะยังคงเป็น useful feature อยู่ดี เพียงแต่ว่า robust feature จะพร้อมใจกันช่วยให้แบบจำลองชี้ไปยังคลาสที่ผิดไปจากเดิม
คราวนี้หากเราทำแบบจำลองที่เทรนได้นี้มาทดสอบกับ test set ดั้งเดิม พิจารณาตัวอย่างข้อมูล $(x, y)$ ใน test set แต่ละตัว เนื่องจาก $x$ ประกอบด้วย robust feature ของคลาส $y$ และ weak feature ของคลาส $y$ เราจะเห็นว่าในแบบจำลองที่เทรนขึ้นใหม่นี้ robust feature ของคลาส $y$ จะถูกนำไปลงคะแนนให้กับคลาส $y’$ แทน ในขณะที่ weak feature ของคลาส $y$ จะยังคงชี้มาที่คลาส $y$ เช่นเดิม ดังนั้นการทดสอบแบบจำลองใหม่นี้ด้วย test set ดั้งเดิม จะเหมือนกับเป็นการประชันพลังในการตัดสินใจระหว่าง robust feature และ weak feature นั่นเอง โดยความแม่นยำบน test set ดั้งเดิมจะสื่อถึงความสามารถในการตัดสินใจของ weak feature
จากการทดลองด้วยชุดข้อมูล CIFAR-10 พบว่าแบบจำลองใหม่มีความแม่นยำ 43.7 % ในขณะที่เมื่อทดลองด้วยชุดข้อมูล $\text{ImageNet}_R$ พบว่าได้ความแม่นยำถึง 64.4 % นั่นแสดงให้เห็นว่าในการเทรนแบบจำลองแบบ standard training นั้น แบบจำลองที่ได้จะมีการตัดสินใจที่ขึ้นกับ weak feature ค่อนข้างมากทีเดียว
References
Prev: การเทรนแบบจำลองด้วย robust features
Next: