คุณสมบัติของ adversarial example
ในหัวข้อก่อนหน้านี้ เมื่อเราได้ค้นพบจุดอ่อนของแบบจำลอง machine learning ทั่วไปและสามารถสร้าง adversarial example ได้ เราก็ได้หาวิธีการเพิ่มความทนทานของแบบจำลองต่อ adversarial example เหล่านี้ รวมไปถึงเทคนิคในการตรวจสอบความทนทานของแบบจำลองกันด้วย อย่างไรก็ดี สิ่งที่เราดูกันมานั้นยังไม่ได้อธิบายถึงสาเหตุความเปราะบางของแบบจำลอง และการมีอยู่ของ adversarial example เหล่านี้ว่าเกิดขึ้นได้อย่างไร
ในหัวข้อนี้เราจะมาทำความเข้าใจเกี่ยวกับสาเหตุของความเปราะบางของแบบจำลองและการเกิด adversarial example โดยเริ่มจากการศึกษาคุณสมบัติของ adversarial example ที่สร้างขึ้นมาได้
การโจมตีข้ามแบบจำลอง
คุณสมบัติแรกของ adversarial example ที่น่าสนใจก็คือ adversarial example จำนวนมากมีความสามารถในการโจมตี ข้าม แบบจำลองได้ กล่าวคือ ถ้าให้ $M_A$ และ $M_B$ เป็นแบบจำลองทาง machine learning ที่เป็นอิสระจากกัน (ไม่จำเป็นต้องมีโครงสร้างแบบจำลองเหมือนกัน) เมื่อเราเทรนแบบจำลอง $M_A$ และ $M_B$ ด้วย training data ที่มีจากการกระจายตัวของข้อมูลแบบเดียวกัน (ไม่จำเป็นต้องเป็น training data ชุดเดียวกัน) จนแบบจำลองทั้งคู่มีความแม่นยำสูง เราจะพบว่า ถ้าให้ $x’$ เป็น adversarial example ที่เราสร้างขึ้นเพื่อโจมตี $M_A$ นั่นคือ ทำให้ $M_A$ ทำนายคลาสของ $x’$ ผิดพลาด เมื่อเรานำ $x’$ นี้ไปทดลองให้ $M_B$ ตัดสินใจ กลับพบว่า $M_B$ ก็ตัดสินใจผิดพลาดด้วยเช่นเดียวกัน นอกจากนี้เมื่อแบบจำลองที่แตกต่างกันทำนาย adversarial example ตัวหนึ่งผิดพลาด ก็มักจะทำนายผิดไปเป็นคลาสเดียวกันอีกด้วย
คุณสมบัตินี้สร้างความสงสัยให้แก่นักวิจัยเป็นอย่างมาก เนื่องจากในการสร้าง adversarial example $x’$ เพื่อโจมตี $M_A$ นั้น เราใช้โครงสร้างของแบบจำลอง $M_A$ เป็นข้อมูลในการคำนวณด้วย แต่ผลลัพธ์ที่ได้กลับสามารถโจมตีแบบจำลองอื่นได้ด้วยเช่นกัน ทั้ง ๆ ที่ไม่จำเป็นต้องมีโครงสร้างแบบจำลองหรือพารามิเตอร์ต่าง ๆ เหมือนกันทั้งหมดก็ได้
นอกจากสร้างปัญหาในมุมมองของนักวิจัยแล้ว คุณสมบัตินี้ก็ยังมีผลกระทบอย่างรุนแรงในระบบต่าง ๆ ที่มีการใช้ machine learning ในส่วนที่สำคัญ เช่นการระบุตัวตนด้วยใบหน้าบน iPhone หรือการตรวจจับวัตถุต่าง ๆ ของรถยนต์ขับเคลื่อนอัตโนมัติ เนื่องจากต่อให้เราไม่รู้ว่าระบบเหล่านี้ใช้โครงสร้างแบบจำลองใดในการตัดสินใจ แต่ตัวอย่างข้อมูลที่เป็น adversarial example นั้นโจมตีข้ามแบบจำลองได้ นั่นแสดงว่า ถ้ามีผู้ไม่หวังดีสร้าง adversarial example โดยอ้างอิงจากแบบจำลองหนึ่ง และนำไปโจมตีระบบที่เกี่ยวข้องกับความปลอดภัยเหล่านี้ ก็อาจจะสามารถโจมตีได้จริง
ทิศทางของการก่อกวน และการกระจุกตัวของข้อมูล
สำหรับตัวอย่างข้อมูล $(x,y)$ ใด ๆ เมื่อเรานำมาคำนวณหา adversarial example $x’$ เราจะเรียกทิศทางของเวกเตอร์ที่ลากจาก $x$ ไปยัง $x’$ ว่า ทิศทางของการก่อกวน เช่นรูปด้านล่างนี้แสดงตัวอย่างการจำแนกรูปตัวเลขออกเป็นสิบคลาส (เลข 0 ถึงเลข 9) โดยรูปเลข 9 ในตำแหน่งกลางกล่องสี่เหลี่ยมแสดงตัวอย่างข้อมูลในชุดข้อมูลจริง และรูปเลข 9 ที่ขอบด้านขวาแสดงตัวอย่าง adversarial example ที่ทำให้แบบจำลองทำนายเป็นเลข 4 โดยกล่องสี่เหลี่ยมแทนขอบเขตของข้อมูลที่มีระยะห่างจากข้อมูลตั้งต้นไม่เกิน $\epsilon$ ทิศทางของการก่อกวนในตัวอย่างนี้แสดงด้วยลูกศรสีเขียว
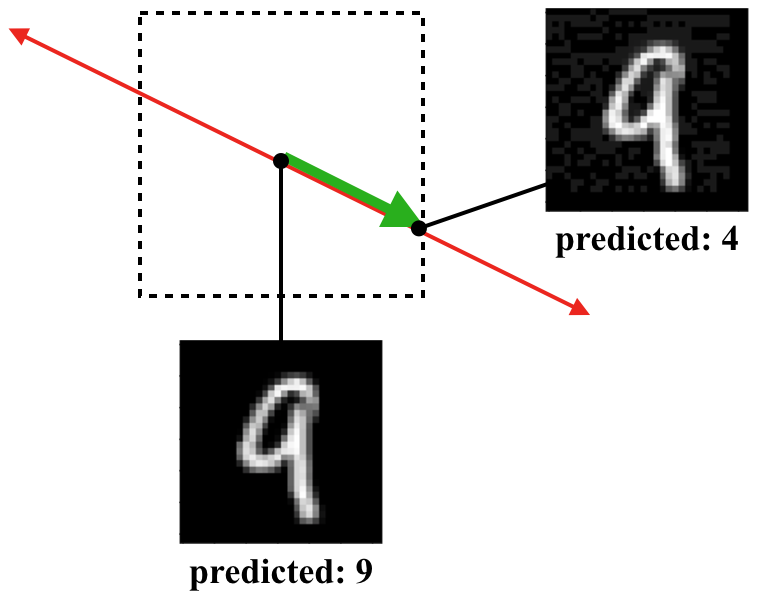
หากเราทดลองนำตัวอย่างข้อมูลที่ตำแหน่งต่าง ๆ ในทิศทางของการก่อกวน (ตำแหน่งต่าง ๆ บนแนวลูกศรสีแดง) มาให้แบบจำลองทำการคำนวณ และนำผลลัพธ์ใน layer สุดท้ายของแบบจำลองก่อนที่จะนำไปคำนวณความน่าจะเป็นด้วยฟังก์ชัน softmax มาพล็อตเทียบกับระยะห่างระหว่างตัวอย่างข้อมูลนั้นกับข้อมูลตั้งต้น $x$ จะได้ผลเป็นรูปด้านล่าง ซึ่งจากรูปจะเห็นว่า บริเวณที่แบบจำลองตอบเป็นเลข 9 ได้ถูกต้อง ซึ่งคือบริเวณที่คะแนนของคลาส 9 สูงกว่าคลาสอื่นทั้งหมดนั้นมีระยะที่แคบมาก นอกจากนี้จะเห็นว่าคะแนนของแต่ละคลาสมีลักษณะเกือบเป็นเส้นตรงตามระยะห่างจาก $x$ นั่นหมายความว่าหากเราทำการโจมตีด้วยทิศทางที่ถูกต้อง เราต้องการเพียงระยะห่างที่มากพอก็จะมั่นใจได้ว่าสามารถโจมตีได้สำเร็จ
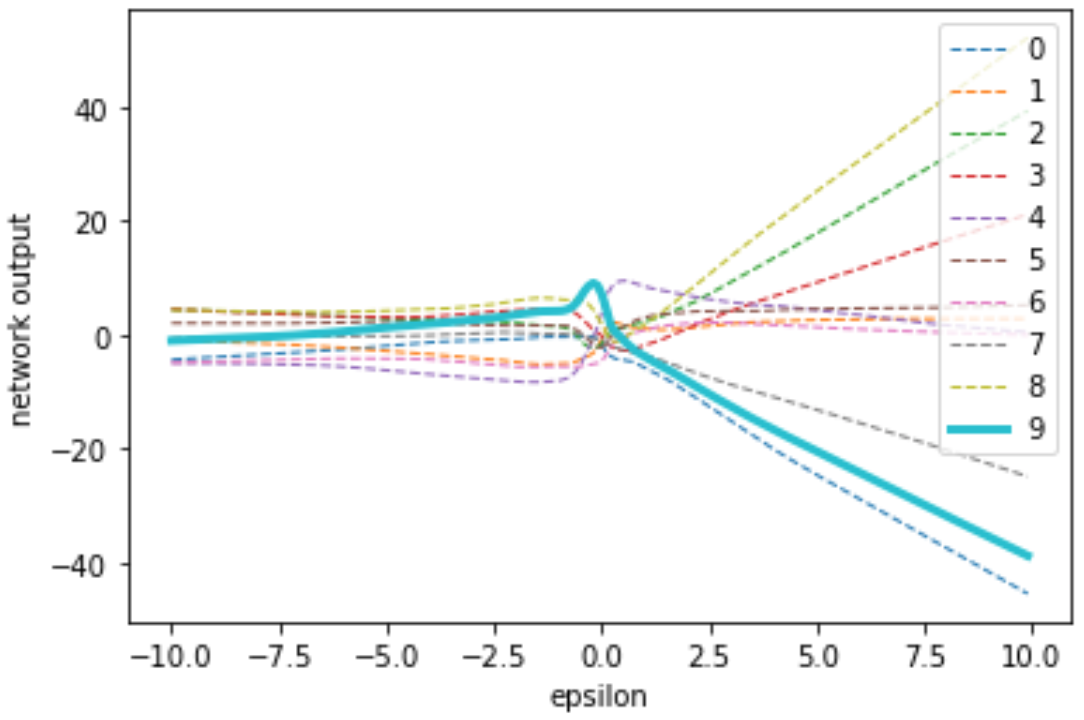
ในการเรียนรู้แบบปกติ การที่ขอบเขตของการตัดสินใจนั้นครอบคลุมตัวอย่างข้อมูลด้วยระยะที่แคบมากเช่นนี้ อาจเกิดจากแบบจำลองของเรา overfit เข้ากับตัวอย่างข้อมูลใน training set มากเกินไป ซึ่งเมื่อนำไปทดสอบกับ test set ก็มักจะเห็นว่าความแม่นยำลดลง เนื่องจากข้อมูลจำนวนมากไม่ได้กระจุกตัวอยู่ในระยะการตัดสินใจที่แคบมากนี้ แต่ในกรณีของเรานี้จะเห็นว่า ต่อให้เราเลือกแบบจำลองที่มีความ generalize ต่อ test data มากแค่ไหน เมื่อพิจารณาในทิศทางของการก่อกวนนี้ก็ได้ผลเช่นเดียวกัน
จากตรงนี้แสดงให้เห็นว่า ในการกระจายตัวของข้อมูลทั้งหมดของเรานั้นยังมีบางทิศทางที่ข้อมูลทั้งหมด (รวมถึง test data ด้วย) มากระจุกตัวอยู่ในระยะแคบ ๆ จึงทำให้เมื่อเราเทรนแบบจำลองด้วยตัวอย่างข้อมูลจากการกระจายตัวนี้ แบบจำลองของเราก็พยายามที่จะดึงคะแนนในบริเวณแคบ ๆ นี้ให้สูงขึ้นโดยไม่สนใจบริเวณรอบข้างแม้จะห่างกันเล็กน้อยแค่ไหนก็ตาม และผลจากการเทรนแบบจำลองที่ได้ก็มีความ generalize พอที่จะนำไปใช้กับตัวอย่างข้อมูลอื่นในการกระจายตัวแบบเดียวกัน
ผลการทดลองนี้ยังช่วยอธิบายความสำเร็จของการทำ adversarial training ได้อีกด้วย เนื่องจากเราทำการหา adversarial example มาใช้ในการเทรน นั่นทำให้แบบจำลองของเราพยายามที่จะดึงคะแนนในบริเวณรอบ ๆ ตัวอย่างข้อมูล โดยเฉพาะในทิศทางที่อ่อนแอเช่นนี้ให้สูงขึ้นไปด้วยกัน ซึ่งจะช่วยทำให้ระยะการตัดสินใจรอบตัวอย่างข้อมูลแต่ละตัวนั้นกว้างขึ้นในทุก ๆ ทิศทางได้ เมื่อเราทำไปทดสอบกับตัวอย่างข้อมูลใน test set ที่กระจุกตัวอยู่แนวเดียวกันกับข้อมูลใน training set จึงได้ว่าขอบเขตการตัดสินใจนั้นครอบคลุมตัวอย่างข้อมูลใน test set ด้วยระยะที่กว้างขึ้นตามไปด้วย
References
Prev: Semidefinite programming relaxation
Next: Useful features